※ 프로시저
함수는 특정 연산을 수행한 뒤 결과 값을 반환하지만 프로시저는 특정한 로직을 처리하기만 하고 결과 값을 반환하지는 않는 서브 프로그램이다. 일반적으로 프로젝트 현장에서는 시스템 설계가 끝난 후 업무를 분할하고 이 분할한 업무 단위로 로직을 구현해야 하는데, 개별적인 단위 업무는 주로 프로시저로 구현해 처리한다. 즉 테이블에서 데이터를 추출해 입맛에 맞게 조작하고 그 결과를 다른 테이블에 다시 저장하거나 갱신하는 일련의 처리를 할 때 주로 프로시저를 사용한다.
1. 프로시저 생성
함수나 프로시저 모두 DB에 저장된 객체이므로 프로시저를 스토어드(Stored, 저장된) 프로시저라고 부르기도 한다.(함수도 스토어드 함수라고도 한다). 프로시저의 생성 구문은 다음과 같다.
기본구문

• CREATE OR REPLACE PROCEDURE: 함수와 마찬가지로 CREATE OR REPLACE 구문을 사용해 프로시저를 생성한다.
• 매개변수: IN은 입력, OUT은 출력, IN OUT은 입력과 출력을 동시에 한다는 의미다. 아무것도 명시하지 않으면 디폴트로 IN 매개변수임을 뜻한다. OUT 매개변수는 프로시저 내에서 로직 처리 후 해당 매개변수에 값을 할당해 프로시저 호출 부분에서 이 값을 참조할 수 있다. 그리고 IN 매개변수에는 디폴트 값 설정이 가능하다.
그럼 jobs 테이블에 신규 JOB을 넣는 프로시저를 만들어 보자. jobs 테이블에는 job 번호, job명, 최소, 최대 금액, 생성일자, 갱신일자 컬럼이 있는데, 생성일과 갱신일은 시스템 현재일자로 등록할 것이므로 매개변수는 총 4개를 받도록 하자.
◈ 예제

성공적으로 컴파일되었다. p_job_id부터 p_max_sal까지 총 4개의 매개변수를 전달받아 이 값들을 jobs 테이블에 입력하고 있다. INSERT문을 사용하므로 COMMIT문을 사용해서 최종적으로 DB에 변경사항을 반영하고 있다.
2. 프로시저 실행
함수는 반환 값을 받으므로 실행할 때 ‘호출’이라고 명명하지만 프로시저는 ‘호출’ 혹은 ‘실행’한다고 표현하는데 실제로는 후자를 많이 사용하는 편이다. 프로시저는 반환 값이 없으므로 함수처럼 SELECT 절에는 사용할 수 없고 다음과 같이 실행해야 한다.
기본구문
① 프로시저 실행

그럼 my_new_job_proc 프로시저를 실행해 보자.
◈ 예제

오류가 나지는 않았지만 제대로 입력됐는지 jobs 테이블을 조회해 보자.


성공적으로 입력됐다. 재차 확인하기 위해 다시 한 번 프로시저를 실행해 보자.

이번에는 오류가 발생했다. 원인은 jobs 테이블의 job_id는 PRIMARY KEY로 잡혀 있는데도 불구하고 동일한 job_id(SM_JOB1)를 또 입력하려고 시도했기 때문이다. 이렇게 기본적인 데이터 무결성 문제는 오라클에서 자동으로 걸러준다. 오라클에게 오류 처리를 맡길 것이 아니라, 동일한 job_id가 들어오면 신규 INSERT 대신 다른 정보를 갱신하도록 프로시저를 수정해 보자.
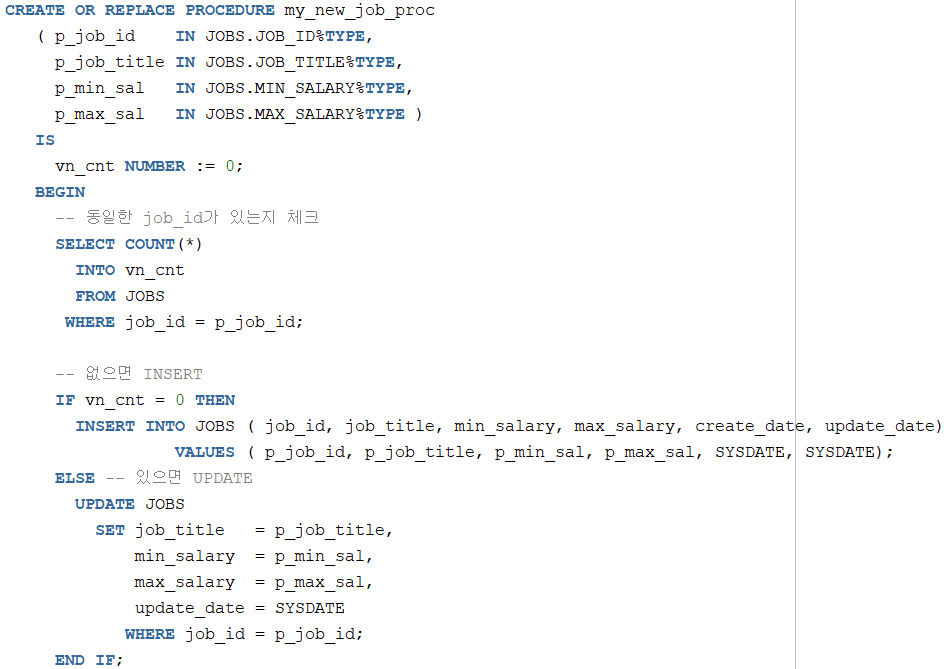

다시 실행해 보자. 이번에는 최소 급여값, 최대 급여값을 수정해서 입력해 보자.
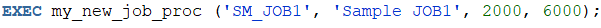


동일한 job_id 값을 입력했더니 INSERT를 하지 않고 매개변수로 전달된 다른 정보를 UPDATE했음을 확인할 수 있다.
프로시저의 매개변수가 많으면 실행할 때 매개변수 값의 개수나 순서를 혼동할 소지가 매우 많다. 이런 경우에는 다음과 같은 형태로 매개변수와 입력 값을 매핑해 실행하면 매우 편리하다.
② 프로시저 실행

‘=>’ 기호를 사용해 해당 매개변수명과 값을 연결하는 형태로 실행할 수 있다. my_new_job_proc 프로시저를 이 형태로 실행해 보자.
◈ 예제




'SQL' 카테고리의 다른 글
| [SQL 25] 예외처리 (0) | 2020.06.12 |
|---|---|
| [SQL 23] PL/SQL 제어문 (FOR 문, CONTINUE문, NULL문) (0) | 2020.06.10 |
| [SQL 22] PL/SQL 제어문 (IF 문, CASE 문, LOOP 문, WHILE 문) (0) | 2020.06.10 |
| [SQL 21] PL/SQL 구성요소 (0) | 2020.06.09 |
| [SQL 20] 서브쿼리 , 인라인뷰 (0) | 2020.06.09 |